


동일 LAN에 있다면 ARP를 사용하여 MAC Address를 얻어올 수 있음 (Data Link layer)
하지만 동일 LAN에 없다면?? 어떻게 통신?
>> 라우터가 개입...^.^ (network layer!!!)
OSI 계층 모델
네트워크 계층의 기능
- [Host의 입장...] datagram 생성
- 송신 호스트 네트워크 계층: 패킷(트랜스포트 계층에서 생성) 데이터를 데이터그램으로 캡슐화 >> 데이터 링크 계층으로 전달
- 수신 호스트 네트워크 계층: 수신된 데이터그램에서 헤더 제거 >> 패킷 추출 >> 트랜스포트 계층으로 전달
- [Router 입장...] datagram 라우팅(routing)
- 데이터그램을 송신 호스트 >> 수신 호스트로 전달
- 다른 LAN에 존재하는 라우터들은 데이터 그램의 IP값을 이웃 라이터로 적절히 전달 (=요거시 바로 포워딩...)
- 라우터: IP 데이터그램 헤더의 필드 값을 참조 >> 데이터그램을 포워딩 할 방향을 정함 (출력 포트 결정~!!)
@ 즉, router의 주 업무는 포워딩 / host는 포워딩 X, 걍 데이터가 오면 받고 데이터 그램을 만든 후 전달
@ host는 P, D.L, N, T(응용계층이 보내는 데이터를 받아야 하기 때문) 총 4개의 계층으로 이루어짐.
@ router는 P, D.L, N(스위칭 할 때 데이터그램의 IP 주소를 받기 때문, 포워딩만 해서 응용 계층이 돌아가지 않음 >> T 계층 필요 없음) 총 3개의 계층을 구현한 하드웨어 장비. 서로 다른 서브 넽웤 간의 다리 역할!!
@ 참고!! Bridge는 P, D.L(IP 주소값을 볼 필요 없기 때문에 N 계층 없음) 총 2개의 계층으로 이루어짐.
라우터 기능
- 라우팅 알고리즘 수행
- 관련 프로토콜의 수행: RIP, OSPF, BGP
- 포워딩 테이블을 적절히 관리(각각의 라우터들의 포워딩 테이블은 다 다름!)
2. 포워딩 동작
-
- 입력 링크를 통해 들어온 데이터를 적절한 출력 링크로 보냄.
- Switching 동작을 수행한다고 볼 수 있음.
- 인터넷의 라우터 == 데이터그램 스위치 == 패킷 스위치 == 패킷 교환망
- 스위칭
X까지 가는 경로가 다양 >> 각 라우터들은 특정 IP값을 어느 쪽으로 보내야 할 지 결정해야 함 >> IP들이 어디에 있는지에 대한 정보를 서로 모아야 함/정보를 주고 받아야 함 ^^7
>> 이런 과정이 라우팅 알고리즘!!!!!!!!!, 그 모여진 정보들이 포워딩 테이블!!!!!!!!!!!
메모리를 사용한 스위칭
- 초기 구현된 라우터가 사용
- 데이터그램을 라우터 메모리(DRAM)로 복사 >> 다시 출력 포트 쪽으로 복사함으로써 포워딩 수행!
- 즉, 입력포트를 통해 들어오는 데이터를 잠시 저장했다가 포워딩 테이블을 보고 다시 읽는 시스템...
- 라우터의 동작 속도: 메모리 읽기+쓰기 하드웨어 속도에 좌우! (한 번의 전송 시 2번의 메모리 접근 필요)
- 메모리 속도가 빠르지 않기 때문에, 스위칭 속도를 크게 높이는데 한계가 존재...
input - memory - output port
버스를 사용한 스위칭
- 데이터그램이 공유된 버스를 통해 출력 포트로 전달
- 라우터의 포워딩 속도: 버스의 데이터 전송 속도에 좌우!
- 한 번에 하나의 데이터그램 포워딩
- 버스에 올리는 데이터 헤더에 출력 포트 번호를 지정하는 방식으로 스위칭
- 하드웨어적으로 설계가 되어 자동적으로 됨
- 메모리 사용 방식에 비해 상대적으로 높은 속도를 요구하는 시스템에 적합...
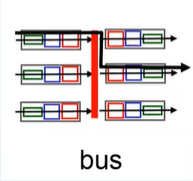
크로스바를 사용한 스위칭
- 버스 형 라우터의 처리 속도를 높인 방법 >> 버스 형을 여러 개 붙여 놓은 것!
- 두 개 이상의 서로 다른 output 포트로 여러 데이터그램을 동시에 전송할 수 있음
- 가장 고속의 시스템 구현 가능. But 컨트롤이 상대적으로 어려워서 구현 가격 상승...
네트워크 계층: 연결 지향 및 비 연결 지향 서비스
: 네트워크 계층은 그 응용에 맞춰 둘 중 하나에 맞춰 구현됨
연결 지향
- 데이터(데이터그램)를 보내기 전에 연결을 미리 확정 / 연결 생성 과정에서 이동 경로 결정
- 데이터 전송이 종료되면 연결 해제
- 특정 연결이 유지되는 동안 데이터의 이동 경로 고정
- 호스트 A가 B로 보낸 데이터: 동일 경로로 이동 >> 데이터 전송 순서와 도착 순서 일치
- 전화 네트워크가 대표적인 연결 지향 방식!!!!
비 연결 지향
- 데이터 전송 전에 연결을 미리 생성 X... 즉, 연결 지향이랑 반대 (당연함)
- 데이터그램 헤더에 있는 도착지 주소 참조 >> 라우터가 각자 포워딩 하는 방식임
- 전송 전에 경로를 미리 정하지 않음
- 호스트 X가 Y로 데이터그램 A, B를 순차적으로 전송 시, A/B의 전송 경로가 다를 수 있음(그럴 수 있다!)
- 사실 중간에 받는 라우터들의 포워딩 테이블이 바뀌지 않는다면? 계속 똑같지 가겠지 뭐..
- 전송 경로는 문제가 생겼을 때(특수 case일 때)만 주기적(매번 X)으로 바뀜. 대부분
- A와 B가 통신할 때, 이 사이에 전기선을 물리적으로 연결 X, 라우터들끼리 알아서 가는 거야. 서킷(회선) X
- 가상 회선 방식 구현을 통해 연결 지향형 서비스 지원 가능
- 인터넷 네트워크가 대표적인 비 연결 지향 방식!~!!
- 포워딩(forwarding)
- 라우터가 입력 링크에서 출력 링크로 데이터 그램을 전송하는 동작. 입력 링크는 정해져 있지 않습니다..
ex) 만약 라우터가 10개라면 그 중 하나가 입력 링크가 될 것이고 나머지들은 출력 링크가 될 것!
- 포워딩 테이블 사용 (라우터가 생성 + 관리)
- 라우팅(routing)
- [전체 네트워크 관점] 출발지 >> 목적지까지 데이터 그램 이동 경로 결정.
- 라우터 간의 정보 교환 + 라우팅 알고리즘을 통해 전송 경로(루트) 정함
- 전송 경로에 위치한 라우터들 각각의 포워딩 동작에 의해 라우팅이 수행...
- 라우팅 알고리즘을 통해 포워딩 테이블의 내용 변경!!
- 라우터
- 라우팅 알고리즘 수행
- 포워딩 테이블(= 포워딩을 위한 데이터 저장) 생성 및 관리
데이터그램 네트워크
- 데이터그램의 전달
- IP(목적지 주소): 데이터그램의 헤더에 저장되어 있음 + 처음에 호스트가 찍은 IP 주소는 안 변햐! 다음은 변함
- 인터넷의 경우, IP 주소가 목적지 주소 + application(패킷)을 전달 ( = 패킷 스위치망, 데이터그램 넽웤)
- 호스트에서 데이터그램을 전송할 때, 호스트는 이동 경로를 미리 정하거나 알 수 없음
- 이동 경로는 라우터들이 동적(주기적으로 천천히...)으로 결정할 수 있음
- 각 라우터는 포워딩 테이블을 참조 >> 입력 포트로 들어온 데이터그램을 적절한 출력 포트로 포워딩
- 포워딩 테이블 데이터가 변경된다면? 당요니 이동 경로도 변경댜
- 비연결지향 네트워크의 특성
- 가는 길이 막히면 데이터가 느려짐 >> 대역폭 보장 X
- 전달 순서의 보장 X
- 비교) 가상회선 방식
- 비연결지향 네트워크에서 연결 회선 네트워크에서와 같은 기능을 흉내
- 현재의 라우터들을 변경하면 더 좋을 것 같지 않니? 근데 사실 안 좋음. 그래서 안 써 (걍 아이디어)
- 이미 경로가 정해져 있으므로 각 연결 별로 대역폭 보장이 어느 정도 가능... 데이터 전달 순서도 보장...
연결지향 네트워크
- 전화망
- 가상(virtual) 회선 네트워크
- 데이터 전송 전에 사용할 가상 회선 설정! 라우터는 대역폭 보자이 불가능하다고 판단하면 연결 설정 거부
- 각 라우터는 설정한 가상회선의 연결 정보 관리. (ex) 가상 회선 번호, 가상 번호에 대한 출력 포트 번호 관리
- 전송 데이터그램 헤더에 가상회선 번호 기록(가상회선 번호가 IP 주소 역할을 한다고 할 수도...)
- 데이터그램 X가 라우터를 지날 때마다 X의 헤더에 쓰여진 가상회선 번호가 변경될 수 있음(인터넷 네트워크 방식과는 차이 有)
- 가상 번호: 각 라우터에서 유니크하게 부여됨 (포트 별로!)
가상회선 연결 방식
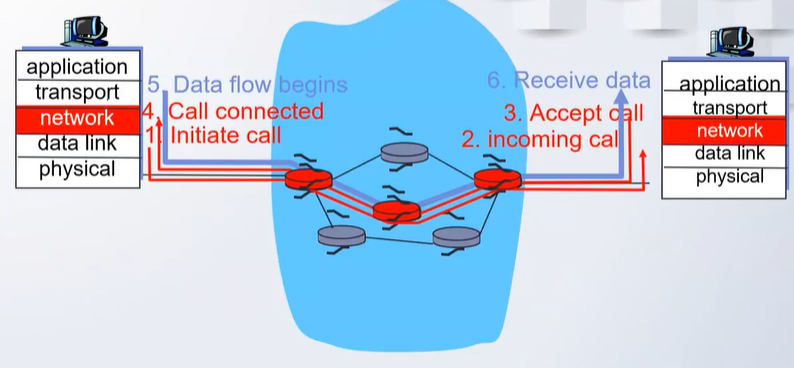
가상회선 포워딩 테이블
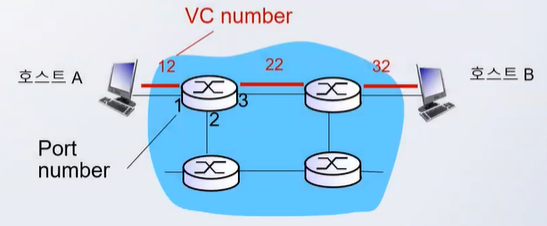
- 가정: 호스트 A에서 호스트 B로 가상 회선 연결
- 호스트 A가 연결 요청: 연결되어 있는 라우터로 연결 요청
- 요청을 받은 라우터는 연결 선상에 있는 인접 라우터로 연결 요청을 보냄
- 이를 반복하여 호스트 B까지 연결 요청이 전달
- 호스트 B가 연결 요청을 수락하면, 해당 경로에 속한 라우터들은 붉은 색 연결을 위해 포워딩 테이블 값 조정
- 연결을 위해 가상 회선용 포워딩 테이블 조정
- 가상회선 번호: 12(X)와 22(Y)번 할당
- 포트별로 unique한 VC 번호 할당
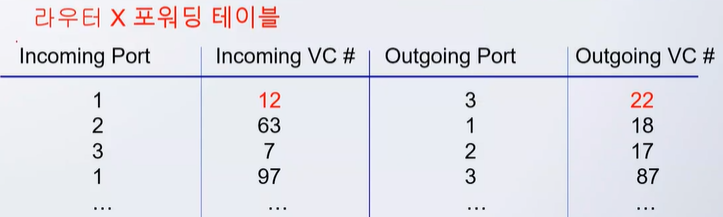
네트워크 전체를 범위로 unique한 번호를 만들기 어려움.. 따라서 각 라우터마다의 유니크한 번호를 만들어용
IP 주소와 도메인(domain) 주소
- IP 주소는 사람이 기억해서 사용하기 어려움 >> 도메인 주소를 사용!
- IP 주소와 도메인 주소와의 연계: DNS(Domain Name System) 서버가 수행
- .com > 영리단체 혹은 개인
- .net > 네트워크 관련 단체
- .org > 비영리 단체 or 개인
- .gov > 미국 연방 정부
- .edu > 대학
IP 주소(version 4)
- IP 프로토콜에서 사용하는 주소. 네트워크 계층 프로토콜에 속함. 중복되면 안 돼용
- 주소 표현 방식: 4바이트(32비트) 데이터 사용 >> 2의 32승 = 대충 40억 개.. 그런데 부족한 상황이여
- IPv4: 32비트 크기의 주소 체계.
서브 네트워크(LAN)를 나타내는 부분 + 서브 네트워크 안에서의 호스트 구별하는 부분으로 나뉨
- 상위 비트는 서브 네트워크 표현! 길이는 가변적.
- 동일한 sub-network에 속한 host들은 동일한 sub-X 값을 가짐.
- 네트워크 크기 확장 >> IP 주소 부족 문제 발생 >> IPv6 (16바이트, 2의 128승)
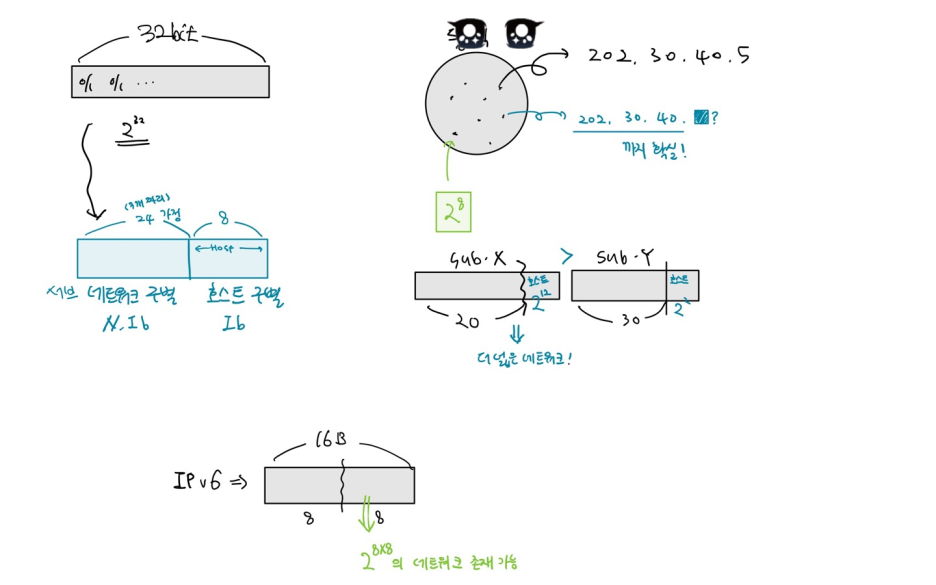
IPv6 주소
- 주소 포맷
- 전체 128 비트로 구성
- 앞 64비트: 서브 네트워크(LAN) 구별용, 뒤 64비트: 호스트 구별용으로 사용
- 서브 네트워크 길이 고정!
- 16 bit 단위 크기로 콜론 삽입
- (ex) 2001:0유8: 85a3:0000:0000:8a2e:0370:7334
- {2바이트를 16진수로 표현하면? 16비트는 4비트(2의 4승)의 길이 표현 가능 >> 따라서 4개 필요}
- IPv4 주소의 IPv6 주소로 표현
- IPv6 주소의 앞쪽 80비트를 0으로 하고, 이어지는 16비트의 값을 모두 1로 함
- 나머지 32비트 크기에 IPv4 주소를 둠
- (ex) IPv6 주소: ffff.192.0.2.128 / IPv4 주소 192.0.2.128
IP Class 주소 체계(1)
초기 개념, 지금은 안 씁니당
- IP 주소: 서브 네트워크 부분 + 호스트 부분
- IP 주소 클래스
- InterNIC에서 ip 주소 관리, 클래스에 따라 IP 할당
- 클래스 종류에 따라 네트워크 크기 결정
- 클래스 A: <0, network # (7 bits)> <host # (24bits)>
- 0으로 시작, 클래스 A에 속하는 sub-network는 2의 7승 개 존재 가능, sub-net은 8비트, 2의 24승 개의 IP
- 클래스 B: <10, network # (14 bits)> <host # (16bits)>
- 10으로 시작, 클래스 B에 속하는 sub-network는 2의 14승 개 존재 가능, sub-net은 16비트, 2의 16승 개의 IP
- 클래스 C: <110, network # (21 bits)> <host # (8bits)>
- 110으로 시작, 클래스 B에 속하는 sub-network는 2의 21승 개 존재 가능, sub-net은 24비트, 2의 8승 개의 IP
- 클래스 D와 클래스 E도 있음 (전자는 multicasting 주소)
- 클래스 A: <0, network # (7 bits)> <host # (24bits)>
IP Class 주소 체계(2)
사용범위
|
Class
|
IP Address
|
Network ID
|
Host ID
|
|
A
|
a, b, c, d
|
a
|
b, c, d
|
|
B
|
a, b, c, d
|
a, b
|
c, d
|
|
C
|
a, b, c, d
|
a, b, c
|
d (2^8개)
|
- 클래스 별 IP 사용 범위 (공인 IP, 인터넷 상에서 라우터들이 인식하는 IP)
- 클래스 A: 1.0.0.1 - 126.255.255.254
- 클래스 B: 128.1.0.1 - 191.255.255.254
- 클래스 C: 192.0.1.1 - 223.255.254.254
- 사설 IP 사용 범위 (가짜 IP?)
- 클래스 A: 10.0.0.0 - 10.255.255.255
- 클래스 B: 172.16.0.0 - 172.31.255.255
- 클래스 C: 192.168.0.0 - 192.168.255.255
네트워크 계층 기능
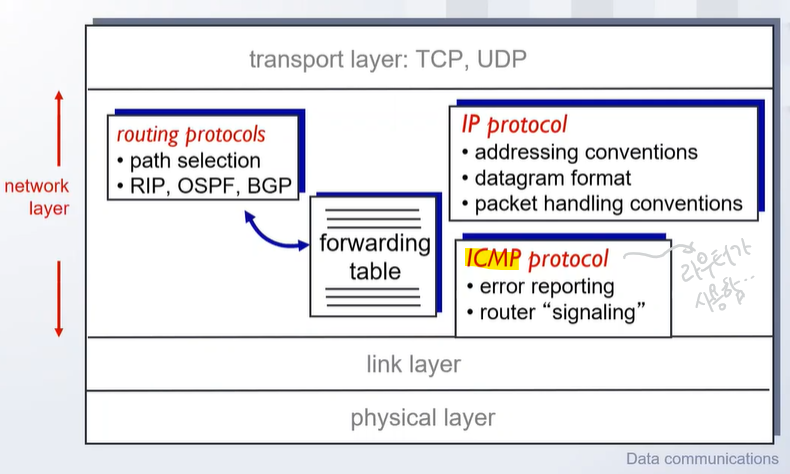
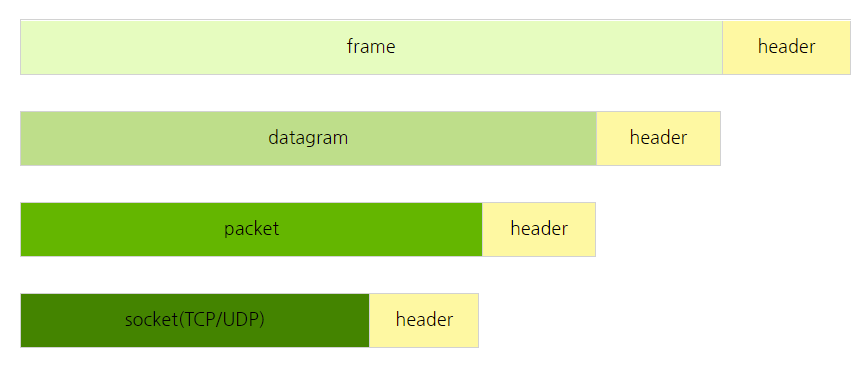
소켓에서 패킷을, 패킷에서 데이터그램을 만들어 보냄!
IPv4 데이터그램 포맷(1)
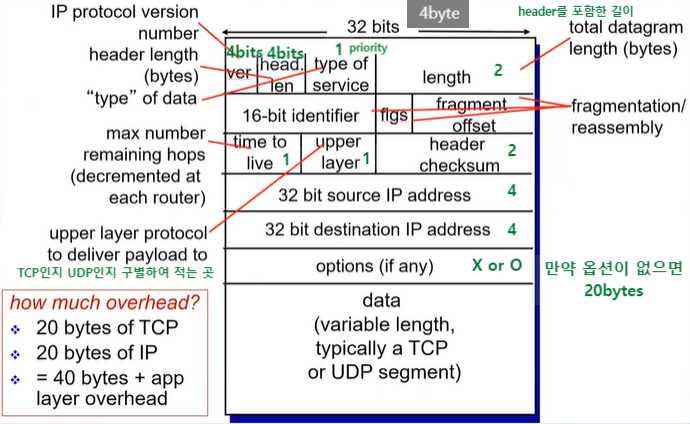
version 4 - (앞부분) 0100
version 6 - (앞부분) 0110
- 만약 options 필드가 없으면 header length도 없어짐
- header는 항상 20바이트 + 옵션이 있다면 더 길어짐 (4의 배수로 맞춰서...)
- 따라서 옵션이 없으면 header length 필요 없음
IPv4 데이터그램 포맷(2)
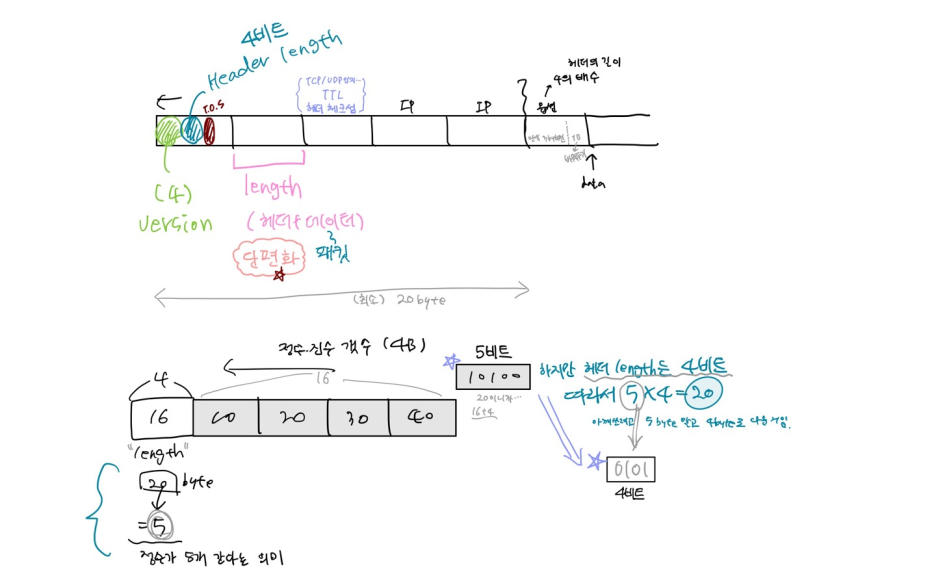
- 가장 앞 부분 4비트: 버전 표시 비트 {0100}
- 헤더 길이 필드: 4비트, 32비트 길이 단위로 헤더의 길이 지정
- 이 필드에 저장되는 값 중 최소값은 5
- Options 필드가 있어서 헤더 길이가 가변적이기 때문에 피료함
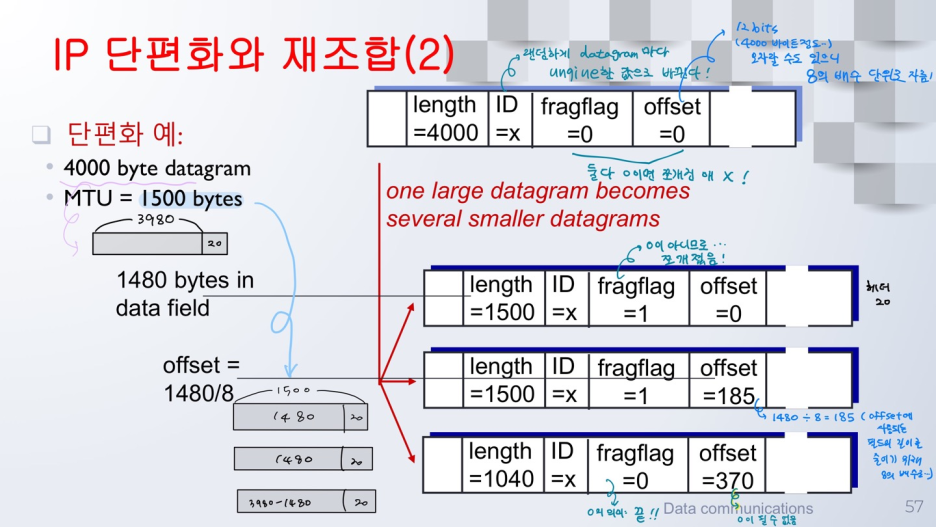
- 데이터그램 길이: 바이트로 계산된 IP 데이터그램(헤더 + 데이터) 전체 길이. 1500 bytes 이하!
- IP 단편화를 다루는 필드
- 인식자 + 플래그(4bits) + 단편화 오프셋;
IPv4 데이터그램 포맷(3)
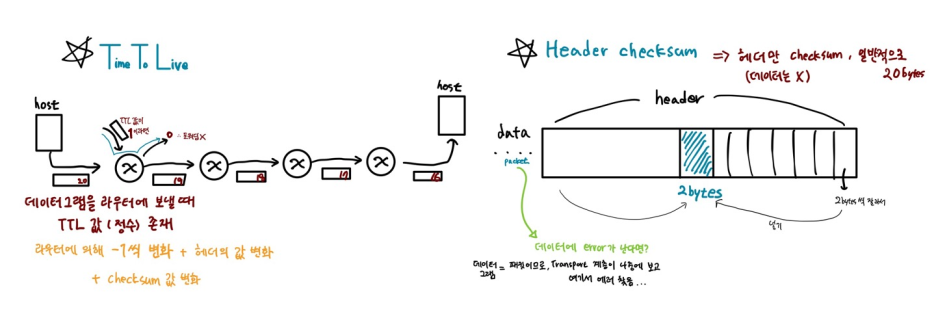
- TTL(Time to live): 라우터는 포워딩 전에 TTL 필드 값을 1씩 감소시킴. 0이 되면 포워딩 X + 라우터는 해당 데이터그램을 폐기
- 프로토콜: 상위 계층의 사용 프로토콜 표시. ex) 6은 TCP!
- 헤더 쳌섬(header checksum): IP 데이터그램의 오류 검출 기능. 헤더에 발생한 오류만 검출(라우터의 오버헤드 고려)
- 출발지 및 목적지 IP 주소 2개 존재
- 보통 20 bytes
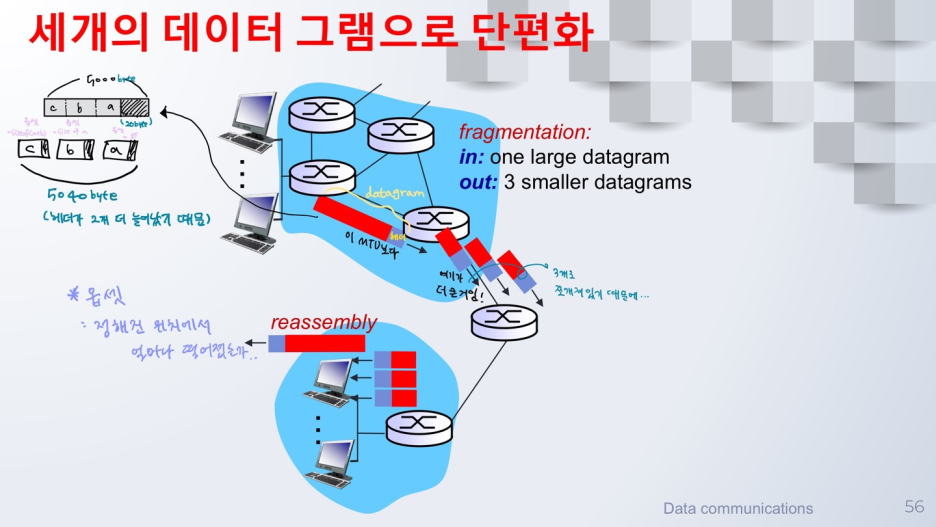
IP 단편화와 재조합 (1)
- 단편화: 이웃 라우터로 전송할 수 있는 데이터그램의 최대 데이터 크기가 존재하므로 데이터를 자르는 것!
- MTU: maximum transfer unit
- 연결 링크의 종류에 따라 MTU의 크기가 다름
- 연결 링크 변화로 인해 어떤 데이터그램은 보다 작은 여러 개의 데이터그램으로 단편화 시켜야 할 필요 O
- ex) router1 ----------- router2 ---- router3: r1에서 온 길이가 긴 데이터그램을 r3로 포워딩할 때, 작은 길이 데이터그램으로 나눠서 전송해야 할 필요 O
- "라우터에서 일어나는 일......"
- 재조합은 수신 호스트에서 수행되는 것이 일반적!!
- 원래 데이터그램으로 모아놓는 것은~~ 최종적으로 해야하무로.. (reassembly 함!!)
IP 단편화와 재조합 (2)
CIDR 주소 체계
- Class 주소 체제의 문제
- 클래스 방식의 경우 서브넷(subnet) 크기가 너무 제한적
- 클래스 A: 27, 클래스 B: 214, 클래스 C: 221
- 구별 가능한 서브넷 개수가 너무 작아서 확장하고 있는 네트워크 환경에 맞지 않음.
- 다양한 크기의 서브넷을 만들 수 있는 방법 필요!!
- 고거시 바로 CIDR (Classless Interdomain Routing, 사이더)
- 기존 class 주소 체계에 비해 다양한 크기의 서브넷을 표현. IP 주소 낭비를 막을 수 있음
- a.b.c.d/x의 형태
- x 값은 서브넷 구별 비트 수
- x값이 크면? 작은 놈!!! (호스트가 작아지기 때문에)
- 라우터는 a.b.c.까지만 관심 있음. d는 host ID 값..
- cmd에서 "Ipconfig"로 콤푸터 서브넷 마스크 확인 가넝
'Study > data' 카테고리의 다른 글
| 신뢰성 있는 프로토콜(FSM, Finite State Machine) (0) | 2023.08.05 |
|---|---|
| 데이터링크 계층(Data Link layer) (0) | 2022.07.13 |